
Otomata & Teori Bahasa
PENDAHULUAN
Teori Bahasa dan Otomata
Teori bahasa dan otomata merupakan bagian dari teori komputasi pada ilmu komputer. Beberapa teori komputasi datang dari bahasa dan rekayasa sistem, terutama yang berbasiskan matematika. Dalam hal ini penekanannya adalah pada pemecahan masalah. Melalui contoh-contoh ilustrasi-masalah dapat dikenali latar belakang dari suatu konsep dan hubungannya dengan definis dan teorema yang ada. Secara teoritis ilmu komputer diawali dari sejumlah berbeda disiplin ilmu; ahli biologi mempelajari neural network, insinyur elektro mengembangkan switching sebagai tools untuk mendesain perangkat keras, matematikawan bekerja berdasarkan logika, dan ahli bahasa menyelidiki tata bahasa untuk bahasa alami (natural language) Finite state automata dan ekspresi reguler awal dikembangkan berdasarkan pemikiran neural network dan switching circuit. Finite state automata merupakan tools yang sangat berguna dalam perancangan suatu penganalisa leksikal (lexical analyzer) yang berguna dalam mengelompokkan karakter-karakter kedalam token-token sebagai unit terkecil dalam mengenali pola. Jadi apa sesungguhnya teori bahasa tersebut ? Teori bahasa merupakan suatu gagasan mendasar dalam komputasi yang menjadi tools untuk mengenali persoalan. Gagasan dasar tersebut dimodel dengan suatu simbol-simbol yang merepresentasikan juga suatu fungsi dari komputer digital. Teori bahasa pada awalnya lebih diarahkan untuk mengenali suatu tata bahasa dan dapat mendefinisikan spesifikasi formal dari tata bahasa tersebut. Sehingga pada akhirnya dapat didefinisikan langkah-langkah algoritmik dalam pemrosesan tata bahasa.
Teori bahasa dan otomata dalam ilmu komputer
Suatu teori hanya menarik jika dapat membantu dalam mencari solusi terbaik. Tanpa penerapan timbul pertanyaan, mengapa mempelajari teori? Teori memberikan konsep dan prinsip yang menolong untuk memahami perilaku dari suatu persoalan yang berkorelasi dengan teori tersebut. Bidang ilmu komputer meliputi topik yang luas, dari perancangan mesin sampai pemrograman. Disamping perbedaan yang ada, terdapat keseragaman prinsip-prinsip umum yang dipakai. Untuk mempelajari prinsip-prinsip dasar tersebut, kita mengkonstruksi suatu mesin otomata sebagai model abstrak dari komputer dan komputasi. Model ini memiliki fungsi-fungsi yang penting dan umum pada perangkat keras dan perangkat lunak komputer. Meskipun model tersebut sederhana untuk diterapkan langsung pada dunia nyata, keuntungan yang diperoleh dari mempelajarinya adalah memberikan landasan untuk basis dari suatu pengembangan algoritma. Pendekatan ini, juga diterapkan pada ilmu sains lainnya.
Abjad, Kata, dan Bahasa
- Abjad adalah himpunan berhingga tak kosong dari simbol.
notasi dari abjad adalah ∑ "sigma"
contoh
∑ : {a,b,c,d,...z}
∑ : {1,2,3,4....}
(a,b,c,d....z & 1,2,3,4....) adalah sebuah simbol. dan jika di kumpulkan dalam satu kurung kurawal maka akan menjadi suatu abjad
- Kata/string/untai adalah Barisan berhingga simbol-simbol dari suatu abjad.
notasi dari kata/string/untai adalah w "w kecil"
contoh
∑ : {a,b,c,d.....z}
w1 = saya
w2 = buku dst
∑ : {1,2,3,4......}
w1 = 1
w2 = 12
w3 = 11 dst
kata kosong/string kosong : Barisan yang kosong dari simbol-simbol
notasi dari string kosong adalah Ɛ
- Bahasa adalah suatu himpunan dari string-string.
notasi dari bahasa adalah L
contoh
L1 = bahasa inggris
L2 = bahasa jawa
L3 = bahasa spanyol dll
Nb: setiap bahasa mempunyai aturan masing-masing, jadi begitu juga dalam otomata dan teori bahasa dalam membuat bahasa harus ada aturannya
contoh
∑ : {1}
w1 = 1; w2 =11; w3 = 111; w4 = 1111 dst
L1={1,111,1111}"aturannya : Genap"
L2={11.1111.111111} "aturannya : Ganjil"
Bahasa Universal adalah suatu bahasa yang bisa mengakomodasi semua string dari suatu abjad
notasi : ∑*
contoh
∑ : {a,b,c}
∑* : {Ɛ,a,b,c,d,ab,aa,cc,....}
∑ : {2}
∑* : {Ɛ,22,2,222,2222......}
contoh sederhana
∑ : {1,2,3}
L : {1,2,3} -> apa aturannya..??
bahasa itu menggunakan aturan "satu state tunggal"
- Operasi-operasi string
-> Panjang (length) dari string
notasi |w|
contoh
w1 = 1 2 1 -> |w1|= 3
w2 = aa -> |w2|=2
-> Perangkaian (concatenation)
contoh
w1 = ab
w2 = 31
w1.w2 = ab.31 -> ab31
->Exponensial (pangkat)
misal w adalah kata
w^n = {Ɛ, jika n = 0}
{w.w^n-1 jika n > 0}
dibaca "w pangkat n, w dikalikan dengan w pangkat n-1"
contoh:
w : ab
w^0 = Ɛ
w^1 = w.w^1-1 = w.w^0 = ab.Ɛ =ab
w^2 = w.w^2-1 = w.w^1 = ab.ab = abab dst
- Operasi-operasi pada Bahasa
-> Perangkaian (concatenation)
misal A dan B adalah Bahasa
A.B={w1.w2|w1 € A & w2 € B}
contoh:
A = {Rumah}
B = {lia,kucing}
A.B = {Rumah lia, Rumah kucing}
-> Exponensial (Pangkat)
misal A adalah Bahasa
A^n = {{Ɛ}, jika n=0}
{A.A^n-1 jika n > 1}
contoh
A = {A,B}
A^0 = {Ɛ}
A' = A.A^0 = {AB}.{Ɛ} = {AB}
-> Gabungan (Union)
misal A dan B adalah bahasa
A U B = {w | w € A atau w € B}
contoh
A : {a,ab,c,d}
B : {c,a,aa,dd}
A U B : {a,ab,c,d,aa,dd}
-> Irisan (Lutesectim)
misal A dan B adalah Bahasa
A n B : {
w | w € A dan w € B }
dari contoh Gabungan di atas maka irisannya adalah {C,A} karna {C,A} ada di A dan juga ada di B
-> Sub bahasa
misal A dan B adalah Bahasa
A C B "dibaca A sub bahasa dari B"
jika semua kata anggota A jika merupakan anggota B
contoh
∑ : {a,b}
a C b = ..?
a : {aa,ab,aab,....}
b : {a,b,aa,bb,ab,aab...}
-> Sama (Equal)
misal A dan B adalah Bahasa
A = B jika Semua anggota A merupakan anggota B dan sebaliknya
A : {a,b}
B : {b,a}
A = B
-> Star Clousure & Plus Clousure
misal A dan B adalah Bahasa
A* ("di baca A star clousure")
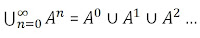

Contoh
∑ : {a} "abjad"
A : {aa} "bahasa"

Klasifikasi Tata Bahasa


Tata bahasa (grammar) bisa didefinisikan secara formal sebagai kumpulan dari himpunan-himpunan variabel, simbol-simbol terminal, simbol awal yang dibatasi oleh aturan-aturan produksi. Pada tahun 1959 seorang ahli bernama Noam Chomsky melakukan penggolongan tingkatan bahasa menjadi empat, yang disebut dengan Hirarki Chomsky.
Penggolongan tersebut bisa dilihat pada tabel berikut:
 |
| Tabel Chomsky |
FINITE STATE AUTOMATA (FSA)
DAN IMPLEMENTASINYA
Finite State Automata (FSA) adalah suatu mesin abstrak yang digunakan untuk merepresentasikan penyelesaian suatu persoalan dari suatu sistem diskrit. Sebagai sebuah mesin maka FSA akan bekerja jika diberikan suatu masukan. Hasil proses adalah suatu nilai kebenaran diterima atau tidaknya masukan yang diberikan. FSA memiliki state yang banyaknya berhingga, jika diberikan suatu simbol input maka dapat terjadi suatu perpindahan dari sebuah state ke state lainnya. Perubahan state tersebut dinyatakan oleh suatu simbol transisi. Mekanisme FSA tidak memiliki memori sehingga selalu mendasarkan prosesnya pada posisi state “saat ini”. Misalnya pada mekanisme kontrol pada sebuah lift, selalu didasari pada posisi lift saat itu pada suatu lantai, pergerakan ke atas atau ke bawah dan sekumpulan permintaan yang belum terpenuhi.
dalam FSA di bagi menjadi 2 jenis yaitu
- DFA (Deterministic FSA) -> memiliki hasil yang pasti
- NFA (Non Deterministic FSA) -> memiliki hasil yang tidak pasti
Secara formal FSA didefinisikan dengan
5 tuple : M = (Q, Σ, δ, S, F), dimana :
Q : himpunan state/kedudukan
Σ : himpunan simbol input
∂ : fungsi transisi
S : State awal (initial state)
F : himpunan state akhir (Final State)
Apa yang dimaksud DFA?
A deterministic finite automaton (DFA)
M = (Q, Σ, δ, S, F), dimana :
Q : himpunan state/kedudukan
Σ : himpunan simbol input
∂ : fungsi transisi, dimana ∂ € Q
x Σ -> Q
S : State awal (initial state)
F : himpunan state akhir (Final State)
Apa yang di maksud NFA?
A Non deterministic finite automaton (DFA) M = (Q, Σ, δ, S,Q0, F), dimana :
Q : himpunan state/kedudukan
Σ : himpunan simbol input
Q0 € Q : initial state
∂ : fungsi transisi, dimana ∂ = Q x (Σ u Ɛ) -> P (Q)
S : State awal (initial state)
F : himpunan state akhir (Final State)
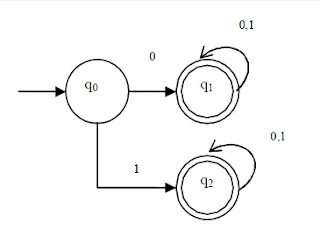
contoh DFA
 |
| mesin DFA |
disebut DFA karena setiap inputan state menerima tepat 1 state berikutnya
Q =
{q0,q1,q2}
∑ = {0,1}
S =
{q0}
F =
{q1,q2}
∂ =
fungsi transisi
∂ (q0,0)
= q1
∂ (q0,1)
= q2
∂ (q1,0)
= q1
∂ (q1,1)
= q1
∂ (q2,0)
= q2
∂ (q2,1)
= q2
Membuat
table transisi
∂ 0 1
q0 q1 q2
q1 q1 q1
q2 q2 q2
contoh NFA
 |
| mesin NFA |
Q =
{q0,q1}
∑ = {0,1}
S =
{q0}
F =
{q1}
∂ =
fungsi transisi
∂ (q0,0)
= q1
∂ (q0,1)
=
∂ (q1,0)
= q1
∂ (q1,1)
= q1
Membuat
table transisi
∂ 0 1
q0 q1
q1 q1 q1
disebut NFA karna ada state yang kosong "Ɛ"
dari contoh-contoh diatas dapat di tulis bahwa perbedaan dari NFA dan DFA sebagai berikut:
Perbedaan NFA & DFA
|
|
DFA
|
Untuk sebuah state yang berlaku bias di
tentukan tepat satu state berikutnya
|
δ
= (s,w) = Q € F
è Dibaca “transisi
dari state awal dengan inputan string w dengan hasil state Q anggota F”
S
= state awal
W
= string
Q
= state initial
F
= final state
|
|
NFA
|
Dari setiap state dengan inputan yang
ada, tidak selalu tepat pada state berukutnya
|
Dari suatu state bias terdapat 0,1
atau lebih busur (transisi) berlabel input yang sama
|
|
δ
= (s,w) = {s} dimana δ (s,w) memuat suatu state di dalam F
|
|


tentu saja
ReplyDeletesiputih
gan gak kebalik antara graf nfa ama dfa nya tuh?
ReplyDelete